Today marks the debut of a new tool called Processing Manager. This tool is designed to simplify the management of processing large tabular models and is compatible for all incarnations of tabular - SSAS, Azure AS and Power BI Premium (using the XMLA R/W endpoint and a Service Principal).
Current Processing Options
Currently, there are several classic methods for processing a model. These common methods are:
Scripting out TMSL for processing specific tables and running it in a window in SSMS, in a SQL job or in a different program (i.e. Azure Data Factory).
Using the Data Refresh API for Power BI Premium models.
Clicking the 'refresh' button for a Power BI dataset within the Power BI Service.
Using PowerShell to loop through tables and process them individually.
Challenges
While each of these methods clearly work, they may not provide enough flexibility when it comes to larger and more complex models. This is for several reasons:
Processing the whole dataset (methods 2&3) may not be feasible because the data volume is too large.
Processing the whole dataset (methods 2&3) may not be desired because data from different sources are made available at different times.
Removing/modifying tables or partitions requires searching for the processing job(s), finding the step(s) that processes the object(s) and removing them.
The Processing Manager tool solves each of these challenges and offers a new level of flexibility using a simple design.
The Tool
The Processing Manager tool runs inside of Tabular Editor. To run the tool, simply download the ProcessingManager.cs code from GitHub and execute it in the Advanced Scripting window in Tabular Editor.
Running the code launches the GUI for the tool. Within the tool, you can create or modify 'batches' and designate which objects (tables, partitions or the whole model) are to be processed in that batch. As shown in the image below, you can set the processing type (i.e. full, data, calculate) for the batch and can also enable the Sequence command by selecting the Sequence checkbox. Selecting the 'Sequence' checkbox allows you to set the Max Parallelism. Note that 'Sequence' and 'Max Parallelism' are both optional.

After customizing your batch, make sure to click the Save button within the tool. This saves your changes back to the model. Note that there is no processing happening at this time. Saving the changes back to the model is simply saving the instructions as metadata back to your model. More explicitly, it is setting annotations within the selected objects back to your model. These annotations are subsequently read by an additional script (ProcessBatches.cs) when you want to process a batch.
Clicking the 'forward' button will take you to a summary page which shows you all the objects which are part of the specified batch (see the image below). Here you can also navigate to see other batches and view their settings.
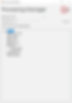
Clicking the 'script' button within the Summary page will dynamically generate a C# script file which will be saved to your desktop. This C# script can be executed in the Advanced Scripting window and will delete and recreate the selected batch within the model. This feature is designed for ALM scenarios where you may want to copy a batch's changes from one version of the model to another (i.e. prod to dev).
Processing the batches
After creating and saving your batch, you can close out of the Processing Manager tool. As you have noticed, we have not actually processed anything as of yet. The tool itself just saves the batch processing instructions within the model.
Now - how do we actually process the batches? For this, we leverage Tabular Editor's command line options. This allows us to submit our batch, connect to our model and process it as we specified in the tool. Below I have summarized the command line code for all scenarios - Power BI Premium, Azure Analysis Services and SSAS. All you need to do is fill in the parameters (in orange).
The first line of the command line code is used to set the batch name (via an environment variable). The -S switch contains the ProcessBatches.cs file which is contained in the GitHub repo along with the tool. The use of the environment variable allows the same ProcessBatches.cs script to be used for processing batches of any/all models.
set batchName=batchName
start /wait /d "C:\Program Files (x86)\Tabular Editor" TabularEditor.exe "Provider=MSOLAP;Data Source=powerbi://api.powerbi.com/v1.0/myorg/<Premium Workspace>;User ID=app:<Application ID>@<Tenant ID>;Password=<Application Secret>" "<Premium Dataset>" -S "<C# Script File Location (ProcessBatches.cs)>"
set batchName=batchName
start /wait /d "C:\Program Files (x86)\Tabular Editor" TabularEditor.exe "Provider=MSOLAP;Data Source=asazure://<AAS Region>.asazure.windows.net/<AAS Server Name>;User ID=<xxxxx>;Password=<xxxxx>;Persist Security Info=True;Impersonation Level=Impersonate" "<Database Name>" -S "<C# Script File Location (ProcessBatches.cs)>"
set batchName=batchName
start /wait /d "C:\Program Files (x86)\Tabular Editor" TabularEditor.exe "<Server Name>" "<Database Name>" -S "<C# Script File Location (ProcessBatches.cs)>"
Here you can see the input and output of running the command line code.

Integration with Azure DevOps
Seeing as the batch processing can be executed via command line, we can transport this part to any program than can run command line code. One such option is Azure DevOps. Setting this up is very similar to the steps outlined in my previous post so if you have not read that I suggest reading it now!
Save the ProcessBatches.cs script to your File Repo.
Follow the steps in my previous post for setting up the Agent Pool, creating a new Pipeline as well as setting up a Service Principal and Key Vault.
Create a new Command line task (must be Task version 2.*).
Within the 'script', simply paste in the command line code shown earlier (an example is shown below as well). As shown in the screenshot below, the only difference here is the reference to Tabular Editor via the WorkFolder, the use of parameters within the Pipeline, as well as appending the script with -V -E -W options. I recommend adding these options when running command line code inside of Azure DevOps as they enable the error/warning messages to appear.
Set the Environment Variable with the desired batch name you want to process.

Here is the code as shown above for processing a batch for a Power BI Premium dataset.
start /wait /d "$(Agent.WorkFolder)\_tool\" TabularEditor.exe "Provider=MSOLAP;Data Source=powerbi://api.powerbi.com/v1.0/myorg/$(Target.WorkspaceName);User ID=app:$(ClientId)@$(TenantId);Password=$(ClientSecret)" "$(Target.Database)" -S "$(Build.SourcesDirectory)\ProcessingManager\ProcessBatches.cs" -V -E -WRunning this pipeline in Azure DevOps will use the ProcessBatches.cs script to read the annotations within the model and process it accordingly. If you examine the code of this script it is using the same method as an earlier post.
Conclusion
The Processing Manager tool and its integration into tools such as Azure DevOps solves all three issues listed earlier in this post. In doing so, it empowers developers to have a heightened level of control and flexibility for processing large tabular models. Make sure to follow the GitHub repo for updates to this tool as well as my main GitHub page for many other tools and techniques!